Ибрар Ахмед. Развенчание мифа о прозрачных огромных страницах (Transparent HugePages) для баз данных
Это перевод статьи: Ibrar Ahmed. Settling the Myth of Transparent HugePages for Databases
Содержание
- Содержание
- Введение
- Изнанка Linux
- Изнанка приложений
- Включение прозрачных огромных страниц
- Проблемы прозрачных огромных страниц
- Тесты производительности
- Компьютер, использовавшийся для тестов
- Тест производительности TPCB (pgbench) – длительность 10 минут
- Тест производительности TPCB (pgbench) – длительность 60 минут
- Тест производительности TPCC (sysbench) – длительность 10 минут
- Заключение
- Выводы
Введение
Понятие огромных страниц существовало в Linux более 10 лет и появилось в Debian в 2007 году с ядром версии 2.6.23. Хотя для большинства задач лучше подходят мелкие страницы, некоторые приложения, интенсивно работающие с оперативной памятью, могут ускориться при использовании страниц памяти большего размера. Использование фрагментов оперативной памяти большего размера позволяет снизить время поиска и увеличить производительность операций чтения/записи. Для включения возможности использования огромных страниц в приложении нужно позаботиться о значительной переработке всего приложения, а это не всегда простая задача. Так появились прозрачные огромные страницы - Transparent HugePages (THP).
Если верить отзывам, прозрачные огромные страницы отрицательно влияют на производительность. В этой заметке я попробую доказать или опровергнуть пользу прозрачных огромных страниц для приложений баз данных.
Изнанка Linux
В Linux, как и в большинстве других известны мне операционных систем, память делится на мелкие фрагменты, называемые страницами. Обычно размер страницы равен 4 килобайтам. Размер страницы в Linux можно узнать с помощью getconf.
# getconf PAGE_SIZE
4096
Новейшие модели процессоров поддерживают страницы нескольких размеров. Однако, в Linux по умолчанию используются страницы минимального размера в 4 килобайта. В случае системы с 64 гигабайтами оперативной памяти получается более 16 миллионов страниц. Связывание этих страниц с физической памятью выполняется модулем управления памятью (memory management unit - MMU) центрального процессора с использованием таблицы обхода страниц - page table walking. Для ускорения поиска страниц центральный процессор оснащён кэшем недавно использованных страниц, который называется буфером сторонней трансляции (Translation Lookaside Buffer - TLB). Чем больше страниц в системе, тем меньший процент страниц умещается в TLB, что приводит к снижению коэффициента попадания в кэш. При каждом промахе мимо кэша происходит более затратный поиск по таблице обхода страниц, что приводит к снижению производительности системы.
А что если увеличить размер страницы? Это позволит уменьшить количество отслеживаемых страниц и уменьшить затраты на обход страниц. Коэффициент попадания в кэш может занчительно вырасти, потому что больше актуальных данных будут помещаться в одной странице, а не в нескольких страницах.
Ядро Linux всегда пытается выделить огромные страницы (если они включены) и, если непрерывный фрагмент памяти необходимого размера не получилось найти в требуемой области памяти, возвращается к страницам с размером по умолчанию в 4 килобайта.
Изнанка приложений
Как уже было отмечено, для использования огромных страниц приложение должно содержать явные инструкции. Не всегда практично изменять для этого само приложение, поэтому был придуман другой подход.
Прозрачные огромные страницы (Transparent HugePages) предоставляются подсистемой ядра Linux, которая предположительно появилась начиная с версии 2.6.38. Если эта подсистема включена, то огромные страницы могут выделяться приложениям так, что они об этом не будут знать, то есть - прозначным образом. Ожидается, что благодаря этому производительность приложения может возрасти.
Я попытаюсь найти причины, по которым прозрачные огромные страницы могут улучшить производительность базы данных. Среди экспертов по базам данных существуют мнения, согласно которым обычные огромные страницы увеличивают производительность, но при использовании прозрачных огромных страниц можно заметить падение производительности. Я решил проделать несколько тестов производительности с разными настройками и под различными нагрузками.
Итак, улучшают ли прозрачные огромные страницы производительность приложений? А точнее, улучшают ли они производительность баз данных? Большинство промышленных стандартов баз данных рекомендуют отключать прозрачные огромные страницы и включить только огромные страницы.
Действительно ли прозрачные огромные страницы снижают производительность баз данных? Пришло время развенчать этот миф.
Включение прозрачных огромных страниц
Текущие настройки можно посмотреть с помощью следующей команды:
# cat /sys/kernel/mm/transparent_hugepage/enabled
[always] madvise never
Временное изменение
Их можно включить или отключить с помощью следующей команды:
# echo never > /sys/kernel/mm/transparent_hugepage/enabled
Фиксация изменений через grub
Или можно поменять параметр grub в файле /etc/default/grub.
Можно выбрать один из режимов прозрачных огромных страниц: включено - enable, выключено - disable или по требованию - madvise. Режимы enable и disable понятны без объяснений, режим madvise позволяет использовать прозрачные огромные страницы приложениям, оптимизированным для использования огромных страниц. Приложение может использовать прозрачные огромные страницы, сделав системный вызов madvise.
Для чего предназначен режим madvise? Обсудим это в следующем разделе.
Проблемы прозрачных огромных страниц
Использование процессора потоком ядра khugepaged
Выдить огромные страницы не так просто, как может показаться на первый взгляд. Обычные огромные страницы резервируются в виртуальной памяти, а прозрачные огромные страницы - нет. Ядро пытается выделить прозрачные огромные страницы в фоновом режиме, а если это не удаётся, тогда использует стандартные страницы с размером по умолчанию в 4 килобайта. Всё это происходит прозрачно для пользователя.
Процедура выделения памяти может задействовать несколько потоков ядра, среди которых kswapd, defrag и kcompactd. Все они отвечают за выделение места в виртуальной памяти для будущих прозрачных огромных страниц. Выделение памяти по требованию выполняется потоком ядра khugepaged, который управляет прозрачными огромными страницами.
Провалы
Поскольку память заранее не зарезервирована, в зависимости от настроек khugepaged, может произойти снижение производительности. При каждой попытке выделить огромные страницы в ядре могут задействоваться несколько потоков, которые отвечают за создание достаточного пространства в виртуальной памяти для выделения прозрачных огромных страниц. Хотя для приложения это проходит незаметно, потребляются дополнительные ресурсы, что может приводить к провалам в производительности, которые могут свидетельствовать о попытке выделить прозрачные огромные страницы.
Раздувание памяти
Огромные страницы подходят не каждому приложению. Например, если приложению нужно выделить только один байт данных, лучше использовать страницу размером в 4 килобайта, а не одну огромную - так память используется эффективнее. Чтобы защититься от этого, предназначен режим прозрачных огромных страниц madvise. В этом режиме огромные страницы отключены на уровне системы, но доступны для приложений, выполняющих системный вызов madvise для выделения прозрачных огромных страниц в области памяти madvise.
Подкачка
Ядро Linux отслеживает страницы памяти и различает страницы, которые используются активно и которые не нужны немедленно. Оно может выгрузить страницу из активной памяти на диск, если эта страница больше не нужна и наоборот - загрузить, если она потребовалась.
Если страница имеет размер 4 килобайта, то операции с памятью предсказуемо быстрые. Однако, при выгрузке страницы размером в 1 гигабайт произойдёт значительный провал в производительности. Когда выгружается прозрачная огромная страница, она делится на страницы стандартного размера. В отличие от обычных огромных страниц, которые зарезервированы в оперативной памяти и никогда не выгружаются, прозрачные огромные страницы выгружаемы и поэтому могут вызывать падение производительности. Хотя в последние годы была сделана масса улучшений производительности в подкачке прозрачных огромных страниц, отрицательное влияние на производительность сохраняется.
Тесты производительности
Я решил протестировать производительность при включенных и отключенных прозрачных огромных страницах. Сначала я в течение десяти минут использовал pgbench - утилиту для тестирования производительности PostgreSQL, основанную на TPCB. В тесте производительности использовался смешанный режим чтения-записи. Результаты теста производительности при включенных и отключенных прозрачных огромных страницах не показали деградации или прироста. Для уверенности я повторил тот же тест производительности в течение 60 минут и получил почти те же результаты. Я также протестировал производительность с помощью утилиты sysbench под нагрузкой TPCC. Результаты были почти теми же.
Компьютер, использовавшийся для тестов
Сервер Supermicro:
- Intel(R) Xeon(R) CPU E5-2683 v3 @ 2.00GHz
- 2 сокета / 28 ядер / 56 потоков
- Оперативная память: 256 гигабайт
- Диск: SAMSUNG SM863 1.9TB Enterprise SSD
- Файловая система: ext4/xfs
- Операционная система: Linux smblade01 4.15.0-42-generic #45~16.04.1-Ubuntu
- PostgreSQL: версия 11
Тест производительности TPCB (pgbench) – длительность 10 минут
На следующих графиках приведены результаты для двух разных размеров базы данных: 48 гигабайт и 112 гигабайт, каждая с 64, 128 и 256 клиентами. При проведении этих тестов производительности все другие настройки оставались неизменными для того, чтобы добиться сравнимости результатов. Бросается в глаза то, что обе линии, соответствующие выполнению со включенными и отключенными прозрачными огромными страницами, по большей части перекрывают друг друга. Это наводит на мысль об отсутствии влияния на производительность.
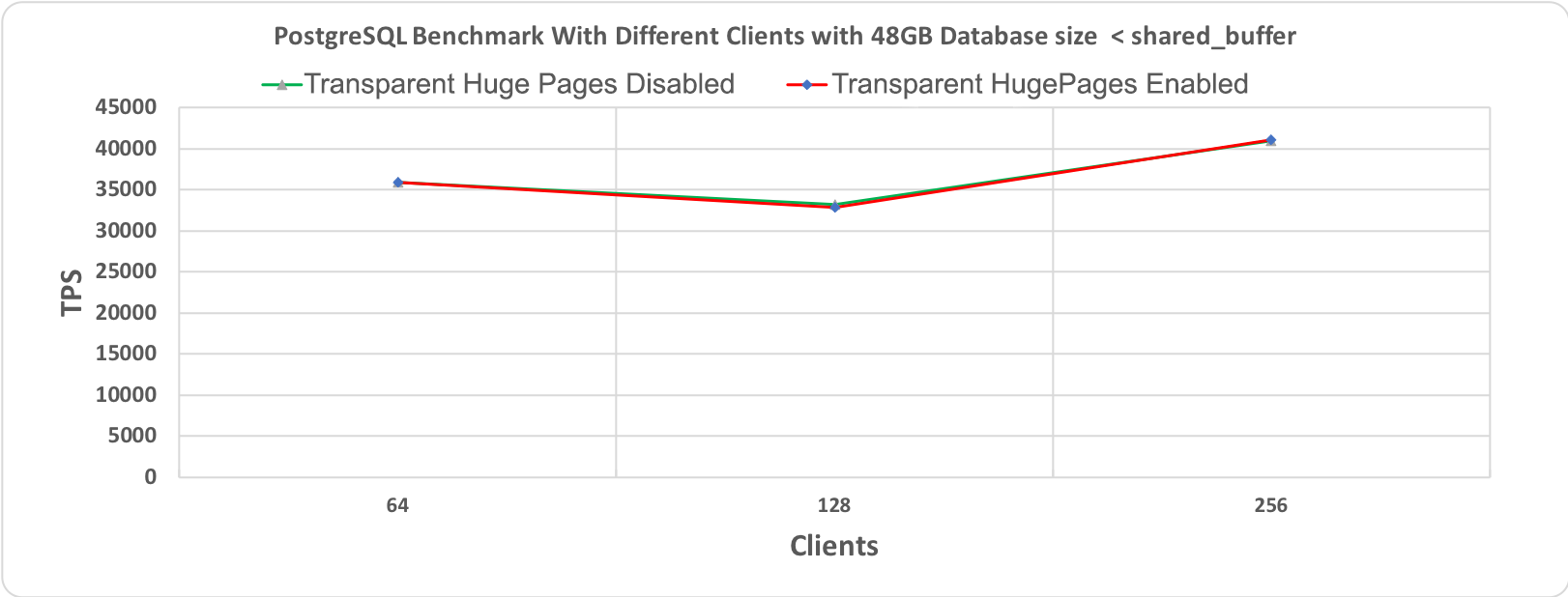
Рис. 1.1 Тест производительности PostgreSQL, длительность 10 минут при размере базы данных (48 гигабайт) < shared_buffer (64 гигабайт)
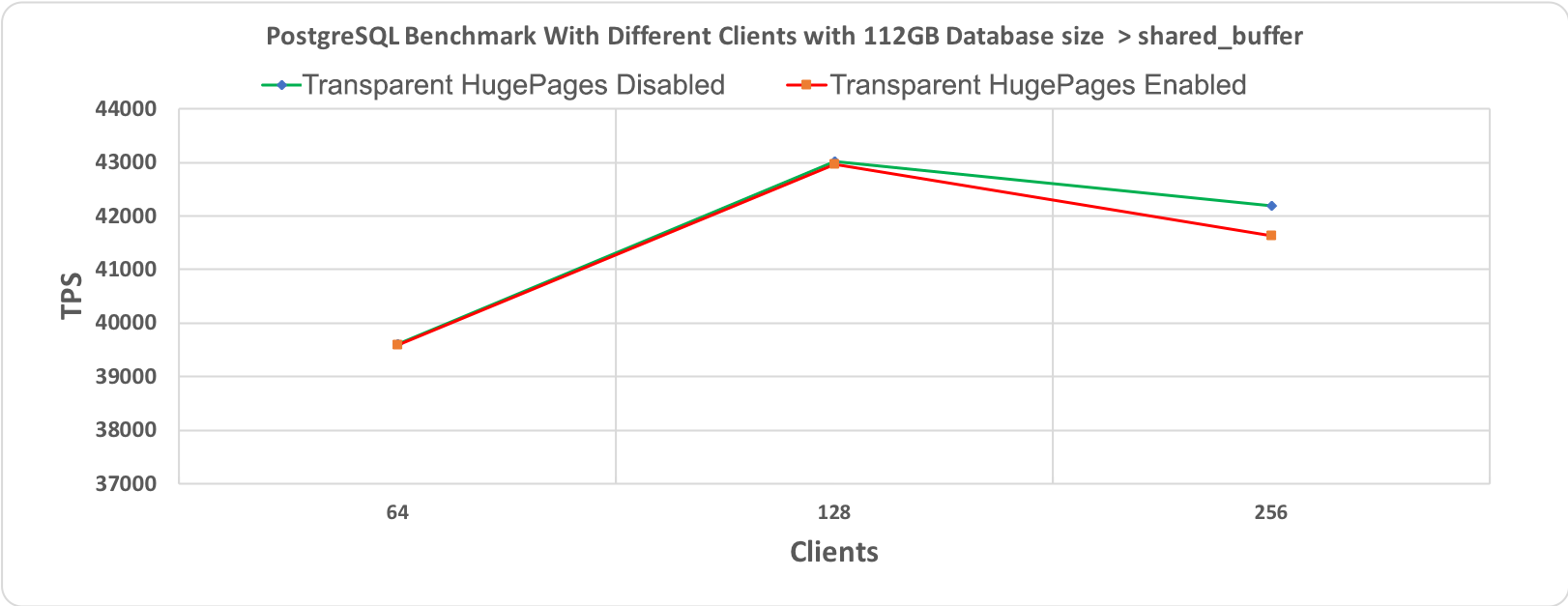
Рис. 1.2 Тест производительности PostgreSQL, длительность 10 минут при размере базы данных (48 гигабайт) > shared_buffer (64 гигабайт)
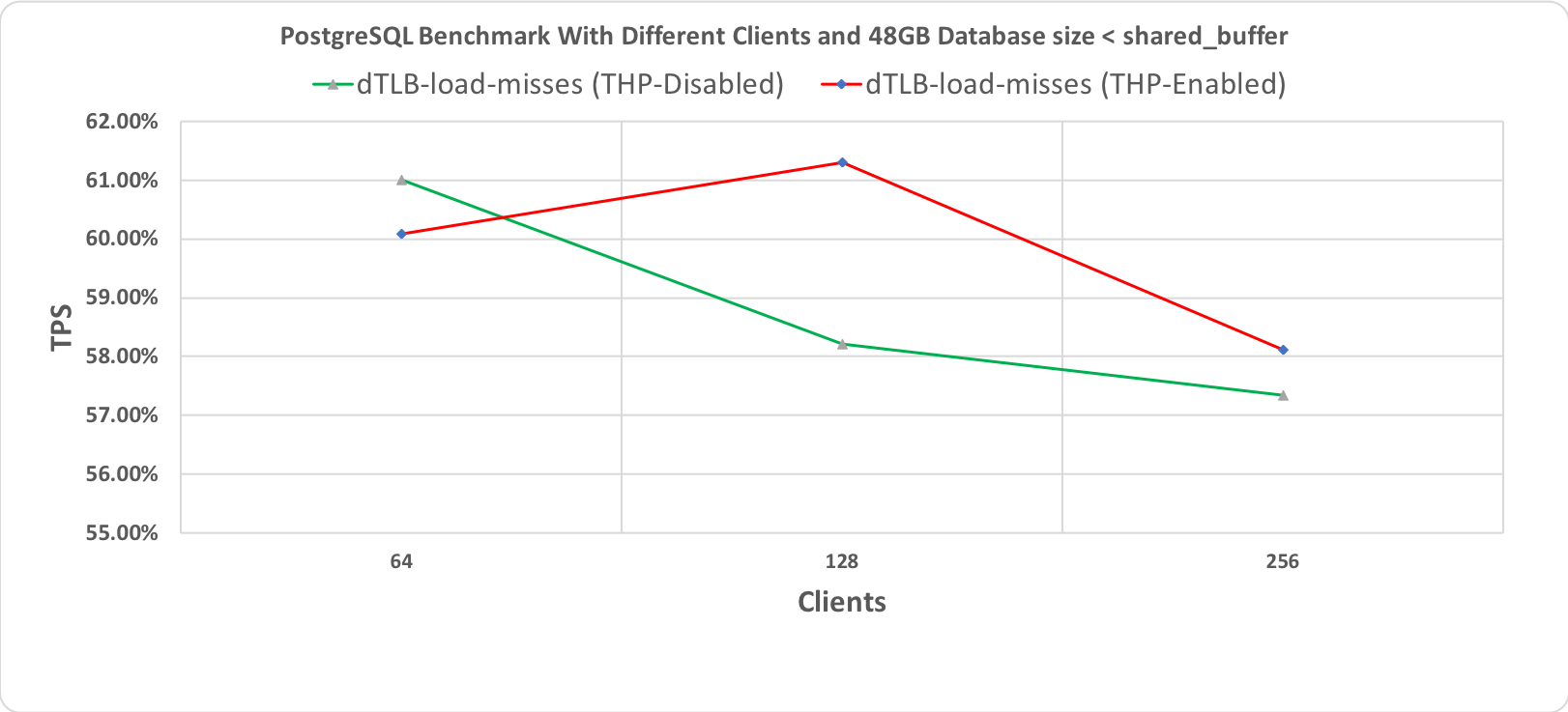
Рис. 1.3 Тест производительности PostgreSQL, длительность 10 минут при размере базы данных (48 гигабайт) < shared_buffer (64 гигабайт) с промахами мимо TLB
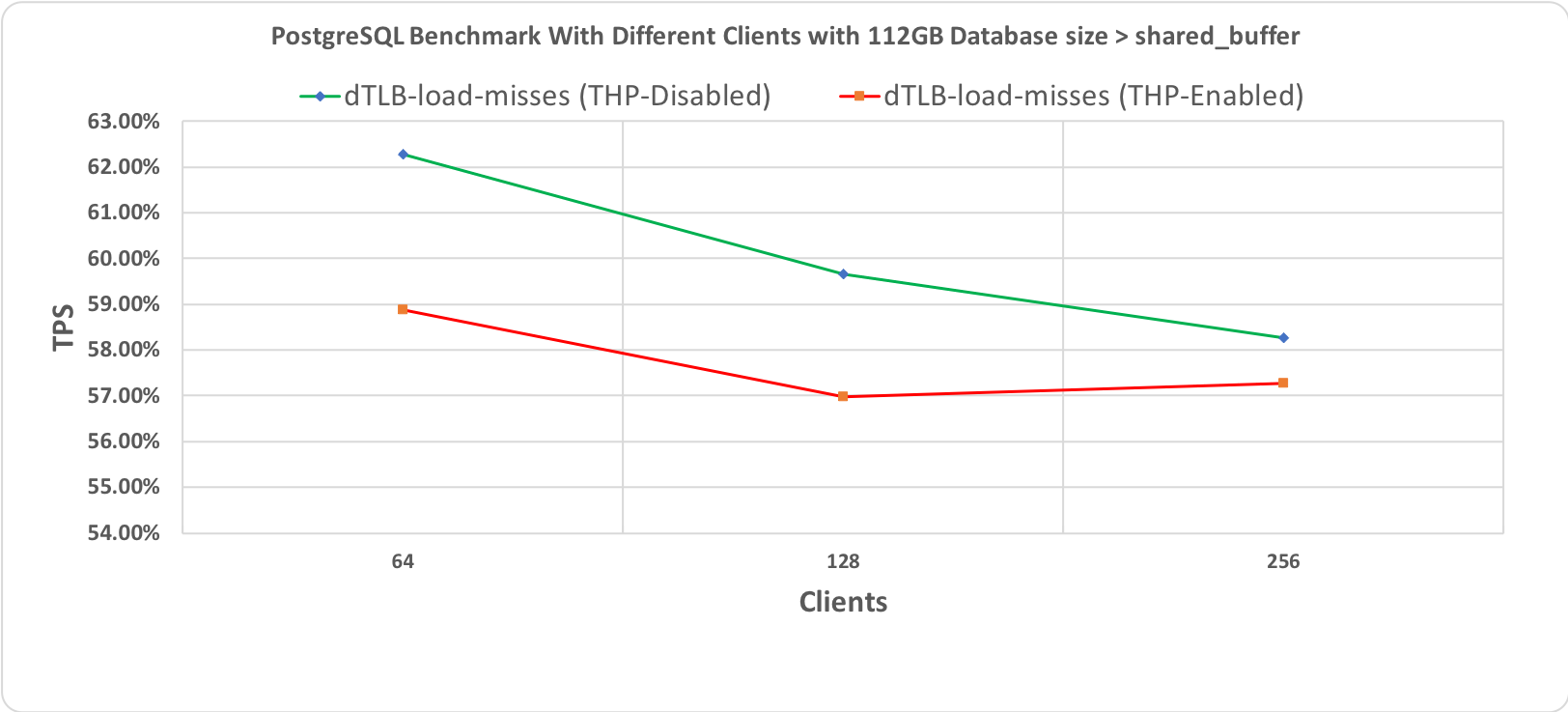
Рис. 1.4 Тест производительности PostgreSQL, длительность 10 минут при размере базы данных (112 гигабайт) > shared_buffer (64 гигабайт) с промахами мимо TLB
Тест производительности TPCB (pgbench) – длительность 60 минут
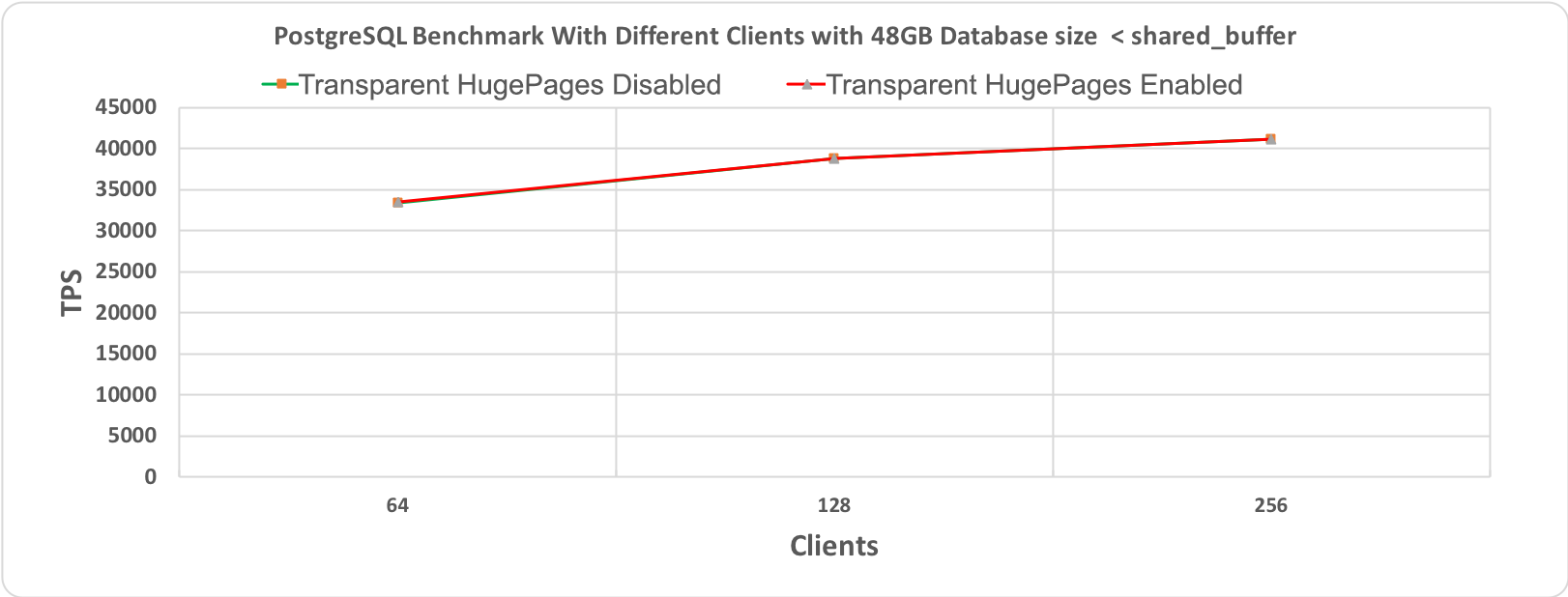
Рис. 2.1 Тест производительности PostgreSQL, длительность 60 минут при размере базы данных (48 гигабайт) < shared_buffer (64 гигабайт)
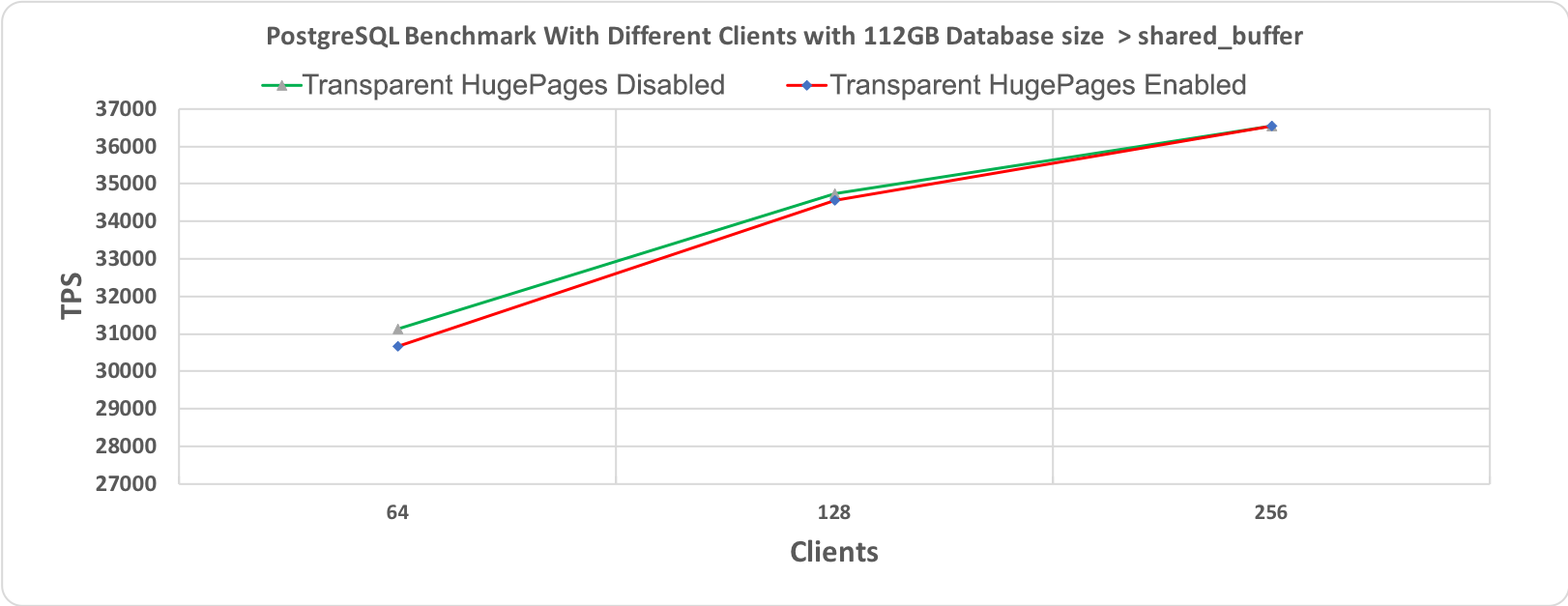
Рис. 2.2 Тест производительности PostgreSQL, длительность 60 минут при размере базы данных (112 гигабайт) > shared_buffer (64 гигабайт)
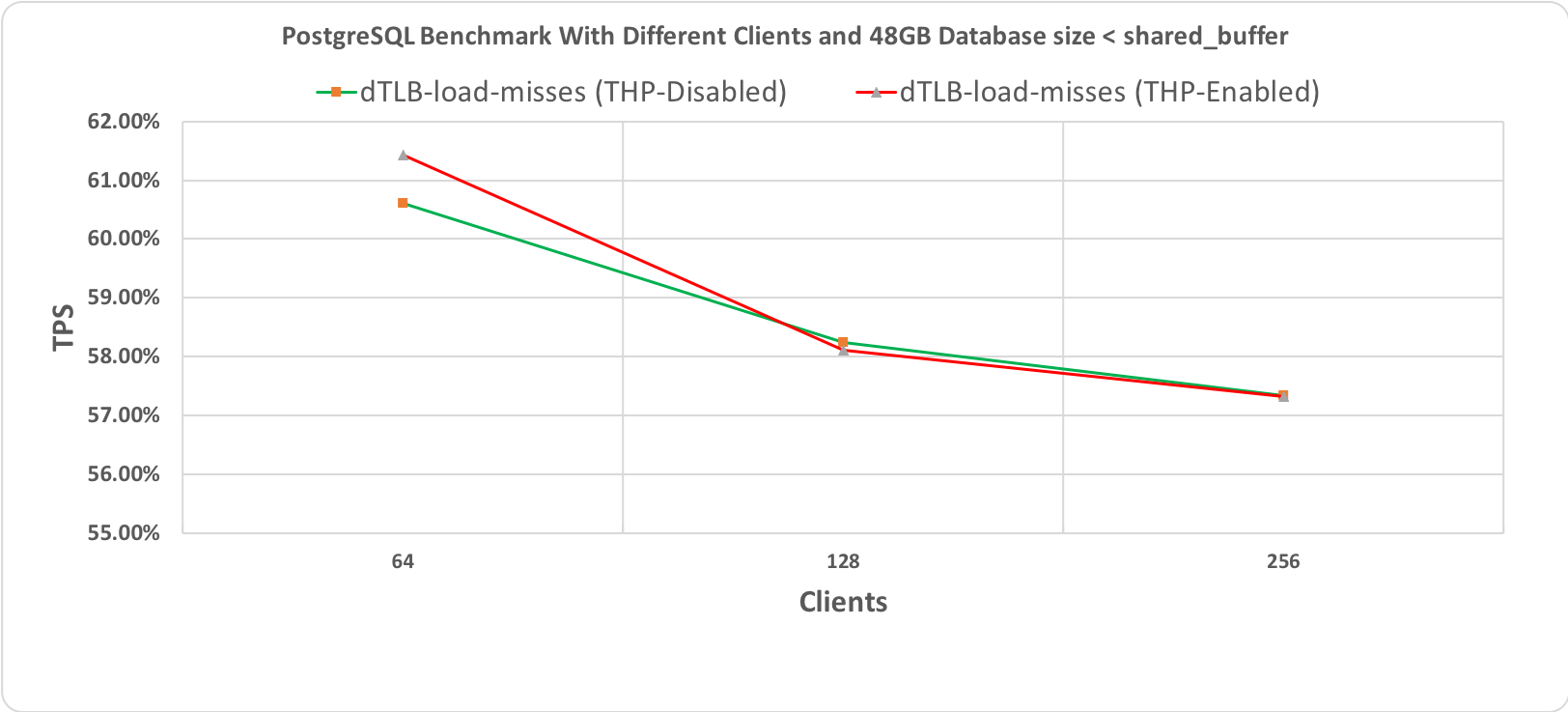
Рис. 2.3 Тест производительности PostgreSQL, длительность 60 минут при размере базы данных (48 гигабайт) < shared_buffer (64 гигабайт) с промахами мимо TLB
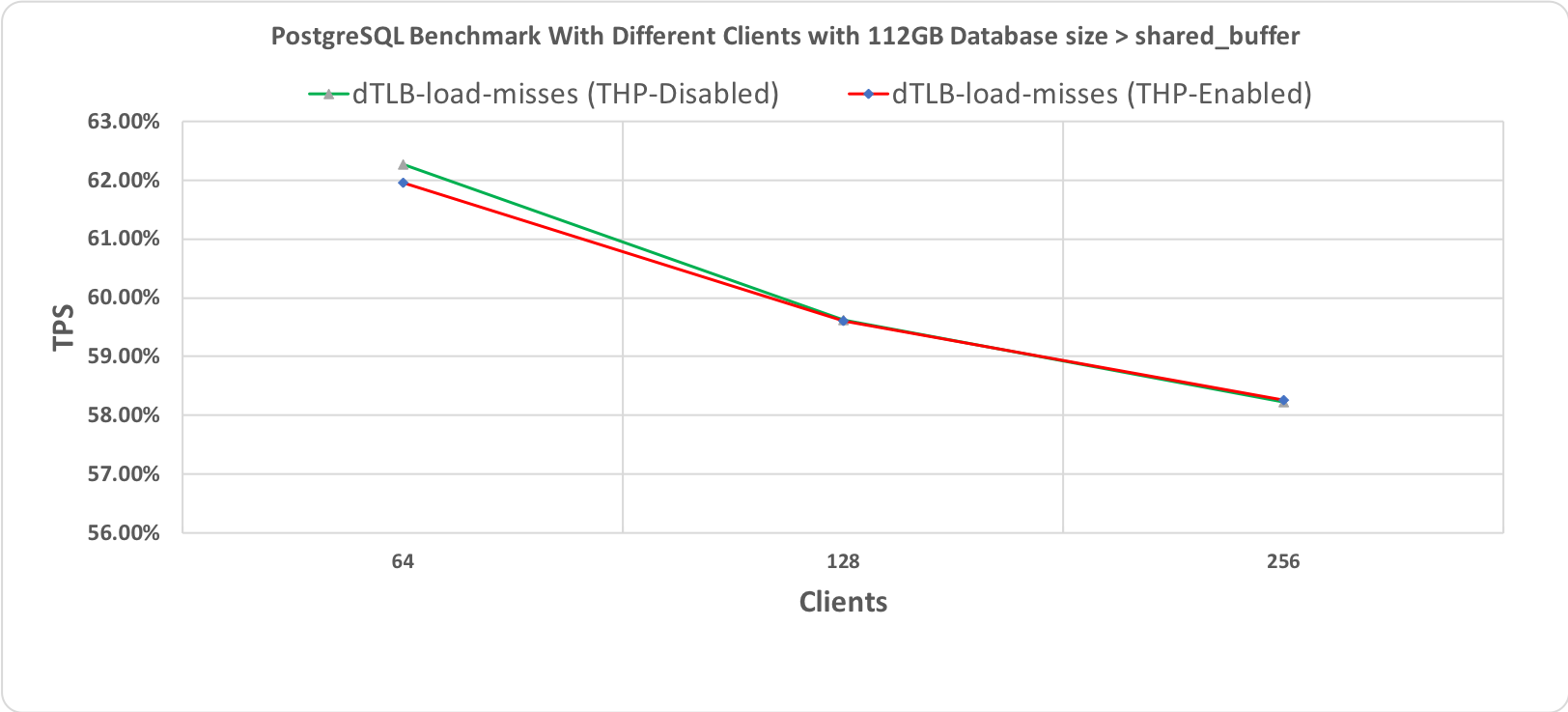
Рис. 2.4 Тест производительности PostgreSQL, длительность 60 минут при размере базы данных (112 гигабайт) > shared_buffer (64 гигабайт) с промахами мимо TLB
Тест производительности TPCC (sysbench) – длительность 10 минут
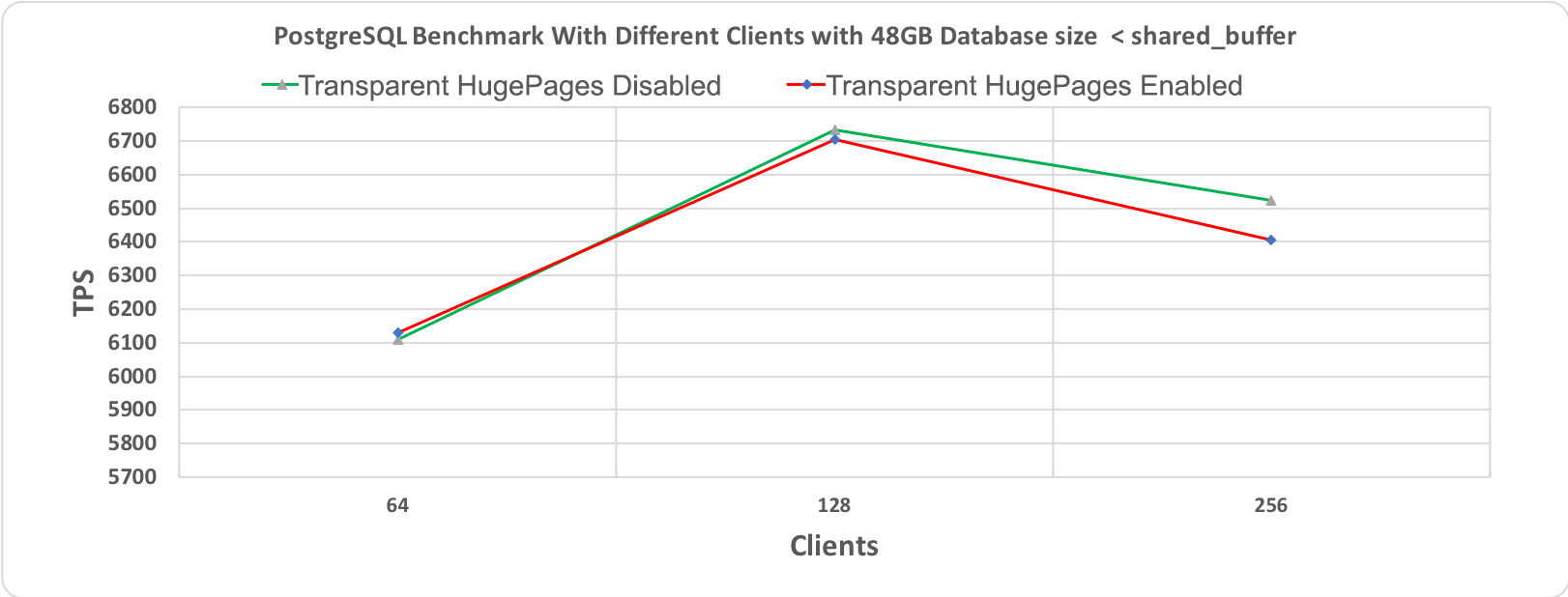
Рис. 3.1 Тест производительности PostgreSQL, длительность 10 минут при размере базы данных (48 гигабайт) < shared_buffer (64 гигабайт)
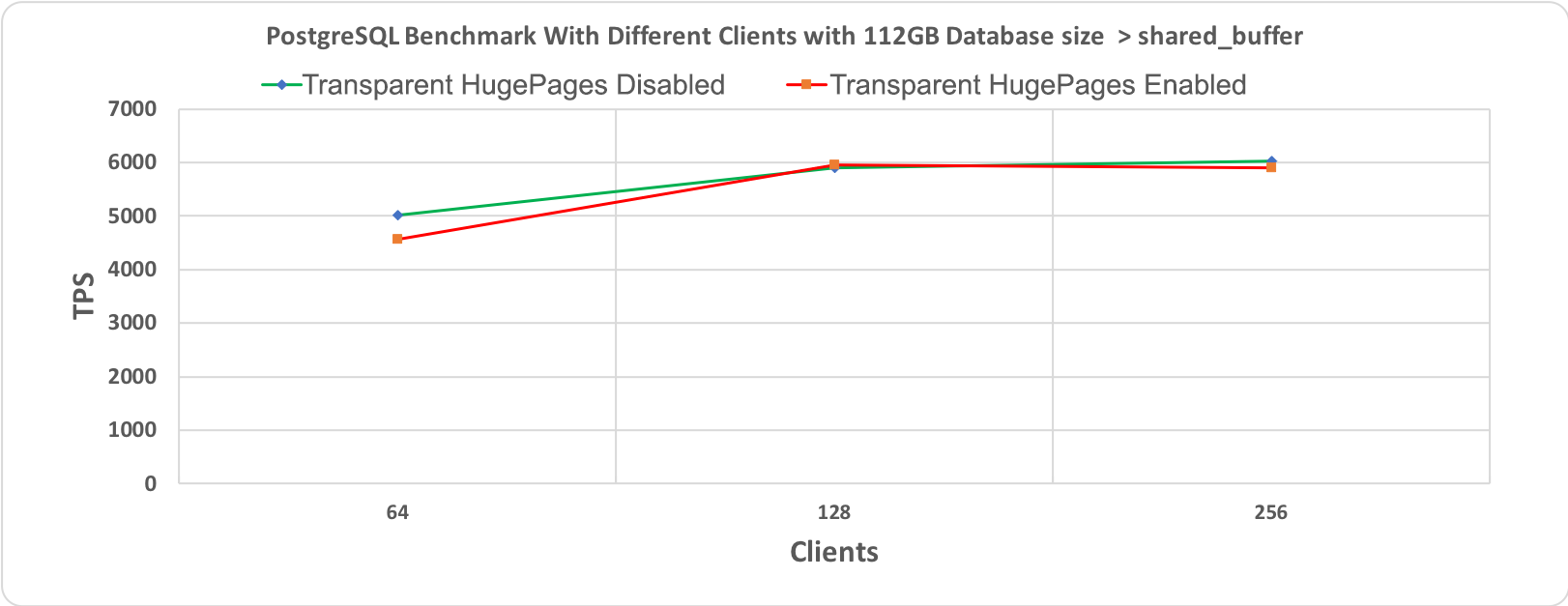
Рис. 3.2 Тест производительности PostgreSQL, длительность 10 минут при размере базы данных (112 гигабайт) > shared_buffer (64 гигабайт)
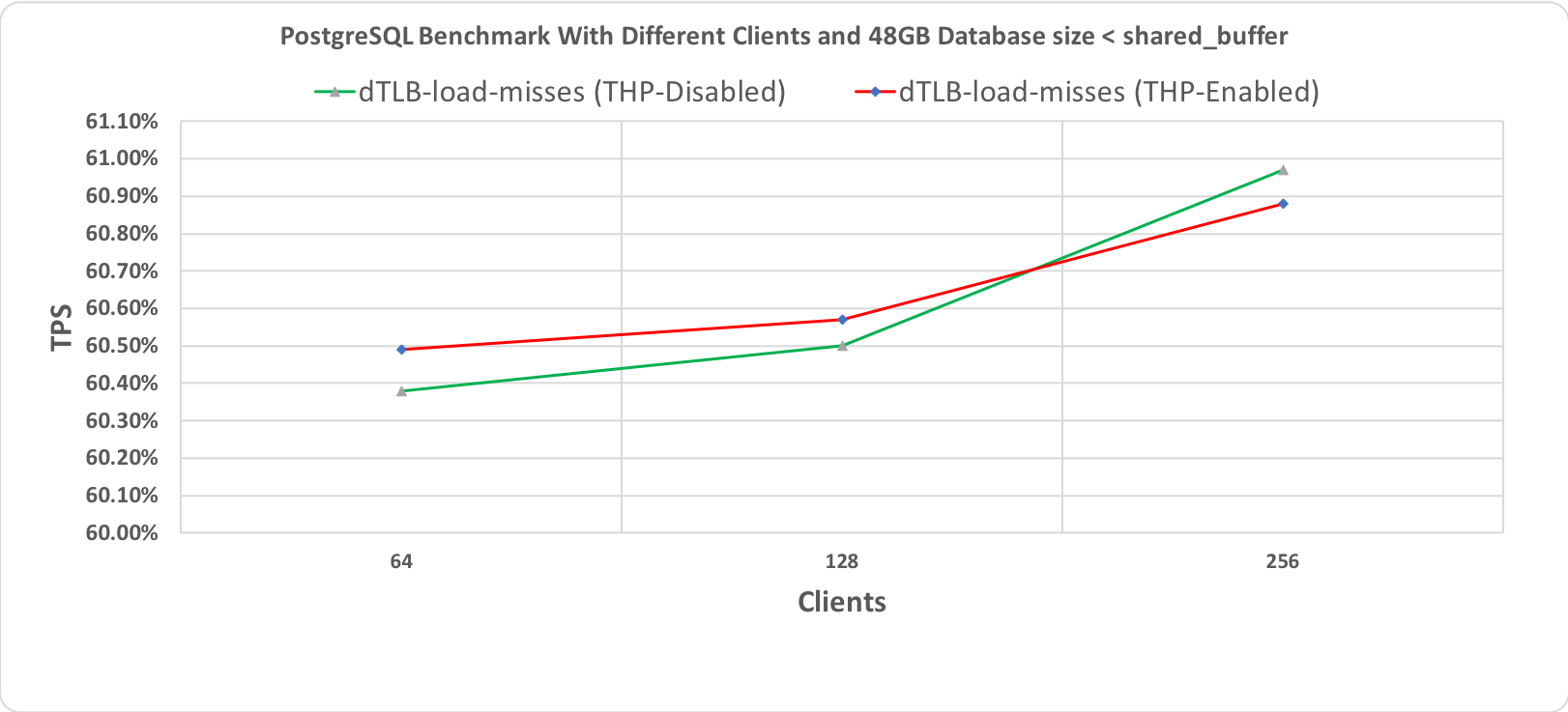
Рис. 3.3 Тест производительности PostgreSQL, длительность 10 минут при размере базы данных (48 гигабайт) < shared_buffer (64 гигабайт) с промахами мимо TLB
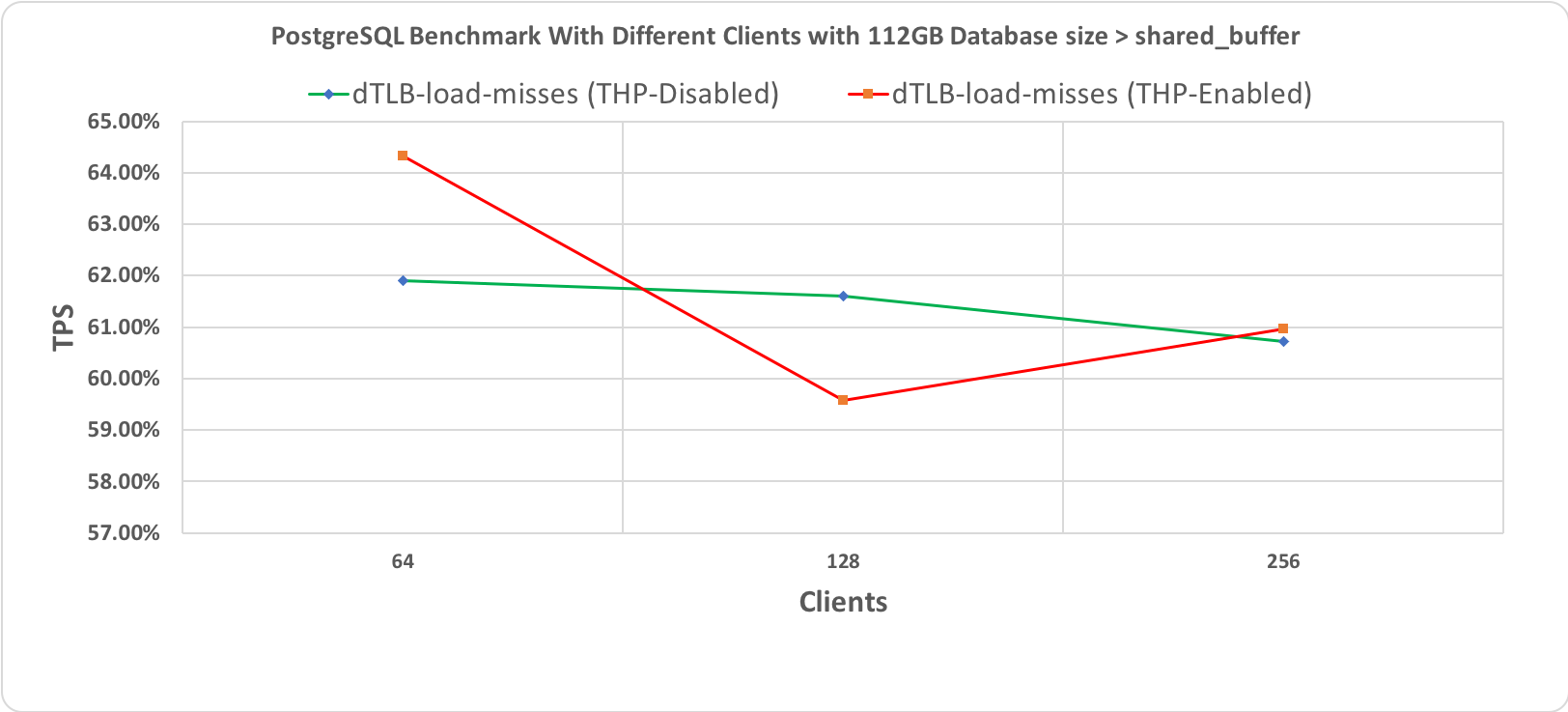
Рис. 3.4 Тест производительности PostgreSQL, длительность 10 минут при размере базы данных (112 гигабайт) > shared_buffer (64 гигабайт) с промахами мимо TLB
Заключение
Результаты получены с помощью разных утилит для тестирования производительности и с применением различных стандартов тестирования производительности OLTP. Результаты ясно показывают, что для данных нагрузок прозрачные огромные страницы имеют отрицательное влияение на общую производительность базы данных. Хотя снижение производительности незначительно, однако совершенно понятно, что ожидаемого роста производительности не наблюдается. Это лишний раз подтверждает рекомендации различных баз данных по отключению прозрачных огромных страниц.
Прозрачные огромные страницы могут быть полезны для различных приложений, но они определённо не дают какого-либо прироста производительности при обработки нагрузки OLTP.
Мы можем уверенно сказать, что "миф" основан на опыте и подтверждён.
Выводы
- Полные данные тестов производительности доступны на GitHub.
- Полные отчёты "nmon", включающие данные об использовании процессора, оперативной памяти и т.д. можно найти на GitHub
- Весь этот тест производительности основан на OLTP. Попробуйте провести тесты производительности OLAP. Возможно прозрачные огромные страницы больше влияют на этот тип нагрузки.